
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬 pandas
- 가설검정
- Django
- rnn
- numpy
- 감성분석
- 기초통계
- 최소자승법
- 회귀분석
- 구글 BERT의 정석
- 다층 퍼셉트론
- 오래간만에 글쓰네
- student t분포
- 기술통계학
- 텐서플로2와 머신러닝으로 시작하는 자연어처리
- 군집화
- 차원축소
- F분포
- 히스토그램
- 밑바닥부터 시작하는 딥러닝2
- Pandas
- 텍스트 분류
- 은준아 화이팅
- 밑바닥부터 시작하는 딥러닝
- 머신러닝
- 결정계수
- 자연어 처리
- 코사인 유사도
- word2vec
- 모두의 딥러닝
- Today
- Total
데이터 한 그릇
분류4)앙상블 학습 배깅, 랜덤 포레스트(Random Forest) 본문
- 랜덤 포레스트의 개요
- 랜덤 포레스트 하이퍼 파라미터 및 튜닝
랜덤 포레스트의 개요
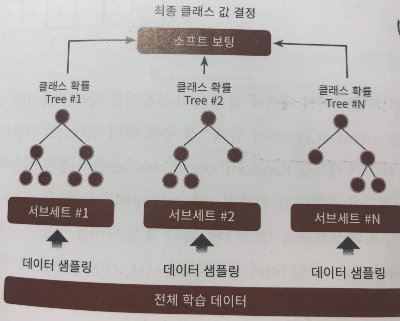
배깅은 앞서 말한 보팅과는 다르게 서로 다른 알고리즘을 합친 것이 아니라 서로 같은 알고리즘으로 여러 개의 분류기를 만들어서 보팅으로 최종 결정하는 알고리즘이다. 배깅의 대표적인 알고리즘은 랜덤 포레스트(Random Forest) 이다. 랜덤 포레스트는 직관적이며, 다양한 영역에서 높은 예측 성능을 보이고 있다.
먼저 원본 데이터에서 서브 데이터로 분류기의 개수에 맞게 샘플링한다. 그 이후 각각의 샘플링된 데이터에서 각각의 분류기들이 예측을 하게 된다. 예측을 통해서 target 변수의 각각의 레이블에 대한 확률값을 도출하게 된다. 이때 모든 분류기들의 각각의 레이블에 대한 확률값들을 소프팅 보팅하여 최종적인 결과값을 반환한다. 이때 개별 분류기들이 학습하는 데이터는 전체 데이터에서 일부가 중첩되게 샘플링된 데이터 세트이다. 이렇게 전체 데이터 세트에서 여러 개의 데이터 세트를 중첩되게 샘플링 하는 것을 부트스트랩(bootstrapping) 이라고 부른다.
랜덤 포레스트 하이퍼 파라미터 및 튜닝
- n_estimators
- max_features
- max_depth
- min_samples_leaf
1. n_estimators
랜덤 포레스트 분류기의 개수, 즉 결정 트리의 개수
분류기가 늘면 보통 성능이 올라가지만 무조건 올라가는 것은 아님
분류기가 늘면 학습 시간이 오래걸림
2.max_features
결정 트리와 같음.
그러나 디폴트 값이 None이 아니라 sqrt
3. max_depth
트리의 과적합을 막기 위해서 트리가 얼마나 뻗어갈지 간섭
4 min_samples_leaf
트리의 마지막 리프의 조건을 조정
리프가 되기 위한 샘플 개수를 정의
값이 크면 과적합 막을 수 있음
5. min_samples_split
과적합 조정
트리가 다음 노드로 나아가기 위해서 필요한 최소한의 샘플 개수를 지정
아래는 GridSearchCV를 통해서 최적의 하이퍼 파라미터를 찾아내고 모델링한 코딩
참고로 best_param_ 을 통해서 나온 값을 다시 랜덤포레스트 모델을 만들 때 집어 넣었음
from sklearn.model_selection import GridSearchCV
params = {
"n_estimators" : [100],
'max_depth' : [6,8,10,12],
"min_samples_leaf" : [8,12,18],
"min_samples_split" : [8,16,20]
}
r = RandomForestClassifier(n_jobs = -1, random_state = 0)
grid_cv = GridSearchCV(r,param_grid = params, n_jobs=-1, cv=2)
grid_cv.fit(X_train,y_train)
print(grid_cv.best_params_)
print(grid_cv.best_score_)
rf1 = RandomForestClassifier(n_estimators = 300, min_samples_leaf = 8,
min_samples_split = 8, max_depth = 10, random_state=0)
'머신러닝 > 분류' 카테고리의 다른 글
| 분류7)앙상블 학습, 부스팅 중 LightGBM (0) | 2021.04.15 |
|---|---|
| 분류6)앙상블 학습, 부스팅 중 XGBoost(eXtra Gradient Boost) (0) | 2021.04.15 |
| 분류5)앙상블 학습, 부스팅 중 GBM(Gradient Boosting Machine) (0) | 2021.04.07 |
| 분류3)앙상블 학습 개요와 보팅 유형 (0) | 2021.04.05 |
| 분류2)분류 머신러닝 개요와 결정 트리 (1) | 2021.04.05 |
